scrape web using scrapy and mongodb
prepare
you’d better do this in a virtual env.
- install mongodb
pip install pymongo# because the mongodb is cs mode database
# you need to install the server
# on ubuntu just use apt command install mongodb
# follow the link: https://docs.mongodb.org/manual/tutorial/install-mongodb-on-ubuntu/
sudo apt-get install -y mongodb-org- install scrapy
pip install scrapydescription
use scrapy to scrapy some new questions from stackoverflow and save the data into the mongodb.
details
if you use the virutal env, make sure you are inside the environment.
scrapy startproject stackoverflow
cd stackoverflow
tree .
├── scrapy.cfg
└── stackoverflow
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py1. edit the items
here we just record the title and url field.
# items.py
class StackoverflowItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()2. create the spiders
before we create the spiders, we need to find out what path we will use to scrapy the data, if you are not familiar with the xpath, you can find more detail in the xpath documents. xpath like a file path in the file system, use xpath the scrapy can find out the data we need.
you can use the web browser to help you find out the xpath.
- use firefox or chrome open the web you want to scrapy.
- select the item you are interested in.
- right mouse key and select inspect elements.
- after you get the html tag, just right mouse key get the xpath.
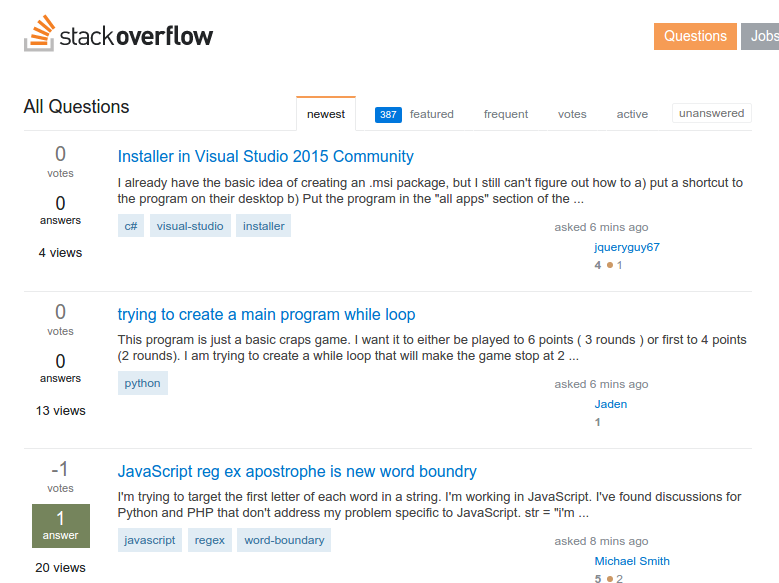
if you select this article title, and follow the step, you will find the xpath of this site is: “/html/body/div/div/article/header/h1”
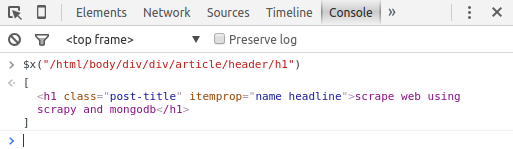
if you want to test if you get the correct xpath, you can use the browser js console to test:
3. ready to create the spiders
- here we just want to scrape the website:
“http://stackoverflow.com/questions” -
we just want to get title and url item as definition in items.py.
- get the xpath of title: “//*[@id=’question-summary-34959124’]/div[2]/h3/a/text()”
notice that: if you want to extract the title text out you need to append text() function. please use the single quote inside the double quote.
- get the xpath of url: “//*[@id=’question-summary-34959124’]/div[2]/h3/a/@href”
notice that: if you want to get the attribute out you need to use operator @ before the attribute of html. please use the single quote inside the double quote.
- inspect the source html structure you may test successfully under the js console inside the browser, but you’ll get error when use the scrapy to scrapy the test out.
what you really want to do is to scrapy the whole list of the question, but now you just scrapy only a specific one.
<!-- question list -->
<div id="questions">
<div class="question-summary"> ... </div>
.
.
.
</div>
<!-- div for each question -->
<div class="summary">
<h3>
<a href="example.com">title</a>
</h3>
</div>4. write the spiders
here comes the source code, do more test in scrapy bash.
# create spider.py inside the spiders/question_newest.py
# or you can use the scrapy to create the spider for you:
# scrapy genspider -t basic question_newest http://stackoverflow.com/questions
"""
this spider crawl the title and url from the
stackoverflow newest questions list.
"""
import scrapy
from stackoverflow.items import StackoverflowItem
stackoverflow_url = u"http://stackoverflow.com"
questions_xpath = "//div[@class='summary']/h3"
class NewestQuestionSpider(scrapy.Spider):
name = "newest_question"
allowed_domains = ["http://stackoverflow.com/questions"]
start_urls = (
'http://stackoverflow.com/questions',
)
def parse(self, response):
questions = response.xpath(questions_xpath)
for question in questions:
item = StackoverflowItem()
item['title'] = question.xpath("a/text()").extract()[0]
item['url'] = stackoverflow_url + \
question.xpath("a/@href").extract()[0]
yield itemtest scrapy
# scrape the stackoverflow newest quesion and save it into the json file.
# if you do not use -o result.json. you won't get any output except log.
scrapy crawl question_newest -o result.json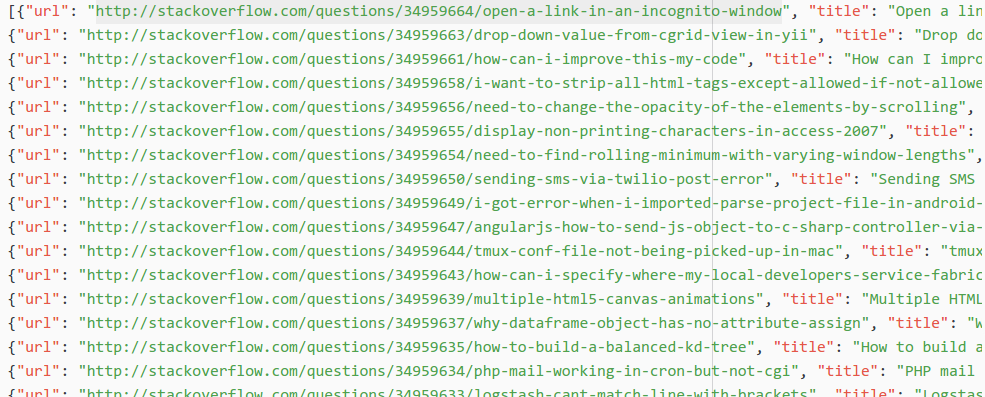
use the mongodb save the result
in scrapy if you want to use the mongodb or other database to save the result( the item return ) to database, you can use the pipeline interface to deal with the item.
you can find settings.py and pipelines.py inside your scrapy directory. just enable the pipeline setting inside the settings.py
# set up the mongodb
MONGODB_URL = "localhost:27017"
MONGODB_DB = "stackoverflow"
# Configure item pipelines
ITEM_PIPELINES = {
'stackoverflow.pipelines.MongodbPipeline': 300,
}customer the pipeline class inside the pipelines.py file:
"""
pipeline to save the question inside the mongodb server.
"""
import pymongo
class MongodbPipeline(object):
collection_name = 'newest_question'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGODB_URL'),
mongo_db=crawler.settings.get('MONGODB_DB', 'defautlt-test')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return itemtest the mongodb
before you run the spider, you need to start the mongod service.
# ubuntu 14.04
sudo service mongod start
# run spider
scrapy crawl newest_question
# after done, check your mongodb
mongo shell
# show database
show db
# switch to stackoverflow
use stackoverflow
# find out data
db.newest_question.find()all done here, hope you’ll enjoy with it.